Querying JSON Ad-hoc in Snowflake
Sometimes I end up with a serialized JSON stored in a relational database (or in a CSV file). It often contains data structures that are…
Sometimes I end up with a serialized JSON stored in a relational database (or in a CSV file). It often contains data structures that are not easy to map to a relational/flat structure and their structure is not fixed by any means. Ad hoc querying of this sort of data is painful, let alone if you need to join relational data to it. But Snowflake hit the nail for me.
I won't elaborate much on what Snowflake is, but for the context of this post let's say it's a modern maintenance-free database, that separates storage from computing, and is capable of joining JSON data with flat tables.
Snowflake offers VARIANT data type for storing structured data (like JSON and some others), but for my ad-hoc processing I am usually too lazy to worry about data types, and I store everything as VARCHAR (or STRING) and cast the correct data type on the fly. One less thing to worry about that Snowflake takes care of.
So let's have a look at my recent use case. My task was to figure out how many (and where) components have primary key columns in output mapping set to non-existing column. The JSON storing the component configuration looks like this
{
"storage": {
"input": {
"tables": [
...
]
},
"output": {
"tables": [
"source": "myfile.csv",
"destination": "in.c-bucket.mytable",
"primary_key": ["Id"]
],
...
}
},
...
}This JSON is stored in a flat table and all other required data is spread across multiple tables. For simplicity the schema can be stripped down to the following
CREATE TABLE "configurations" (
"idProject" STRING,
"idComponent" STRING,
"idConfiguration" STRING,
"configuration" STRING // serialized JSON of the config
);
CREATE TABLE "columns" (
"idProject" STRING, // joins on idProject column
"idTable" STRING, // joins on destination attribute in the JSON
"name" STRING // column name
);So what I want to do is to compare column names in the table columns with the content of the JSON configuration. First of all I need to flatten the JSON stored in the configuration column. Snowflake offers FLATTEN function to normalize structured data. Additional LATERAL keyword allows me to add rows from the result to the original table.
SELECT
"configurations"."idProject",
"configurations"."idComponent",
"configurations"."idConfiguration",
flatten.*
FROM
"configurations",
LATERAL FLATTEN(input => PARSE_JSON("configuration")) flatten;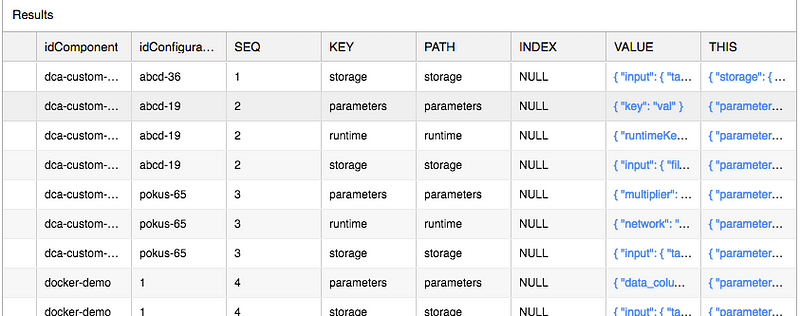
The last 6 columns are the decomposed JSON. VALUE column stores value from the current node identified by KEY (object) or INDEX (array). As you can see, configuration pokus-65 has 3 root nodes — parameters, runtime and storage (this is our interest), each of which has it's own row in the result. And now I can dig further.
SELECT
"configurations"."idProject",
"configurations"."idComponent",
"configurations"."idConfiguration",
outputMappings.*
FROM "configurations",
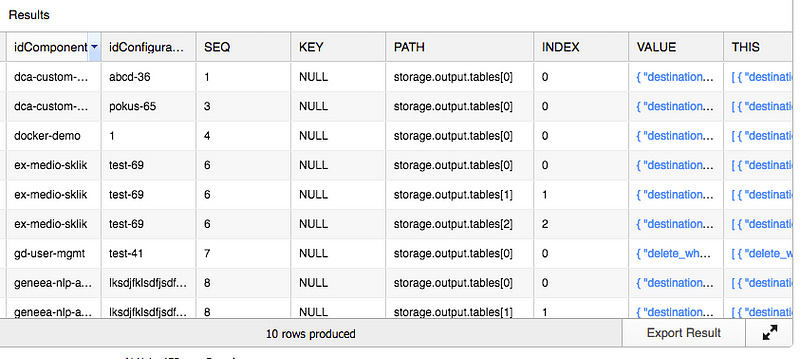
LATERAL FLATTEN(input => PARSE_JSON("configuration"), path => 'storage.output.tables') outputMappingsIn the FLATTEN function you can specify the path to extract. Now we have each array item in the storage.output.tables node on it's own row.
Primary key is another array, so that requires another FLATTEN in the query.
SELECT
"configurations"."idProject",
"configurations"."idComponent",
"configurations"."idConfiguration",
outputMappings.VALUE:"destination" AS "idTable",
primaryKeys.VALUE AS "primaryKeyColumn"
FROM "configurations",
LATERAL FLATTEN(input => PARSE_JSON("configuration"), path => 'storage.output.tables') outputMappings,
LATERAL FLATTEN(input => outputMappings.VALUE, path => 'primary_key') primaryKeys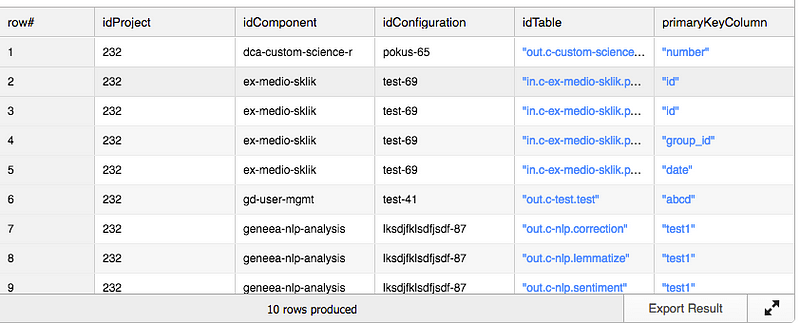
We have extracted the idTable column (note the colon, which is a syntactic shortcut for GET_PATH function) and also all columns of the primary key. And now we're back to basic SQL and some JOINs.
SELECT
"primaryKeys".*,
"columns"."name"
FROM (
SELECT
"configurations"."idProject",
"configurations"."idComponent",
"configurations"."idConfiguration",
outputMappings.VALUE:"destination" AS "idTable",
primaryKeys.VALUE AS "primaryKeyColumn"
FROM "configurations",
LATERAL FLATTEN(input => PARSE_JSON("configuration"), path => 'storage.output.tables') outputMappings,
LATERAL FLATTEN(input => outputMappings.VALUE, path => 'primary_key') primaryKeys
) "primaryKeys"
LEFT JOIN "columns" ON
"primaryKeys"."idProject" = "columns"."idProject"
AND "primaryKeys"."idTable" = "columns"."idTable"
AND LOWER("primaryKeys"."primaryKeyColumn") = LOWER("columns"."name")
WHERE
"columns"."name" != "primaryKeys"."primaryKeyColumn"
OR "columns"."name" IS NULL;I used the previous query as a subquery and LEFT JOINed the columns table case insensitively using column name. The WHERE clause then filters out all matches and leaves us with missing or case-mismatch columns.
All queries were executed on sample datasets with ~10k rows in the configurations table and ~600k rows in the columns table. Duration on a small Snowflake warehouse never exceeded 1s. For me it is by far the fastest of all options including writing a custom script to parse and validate the data.