Parsing JSON in Papertrail
From a bookmarklet to Chrome Web Store
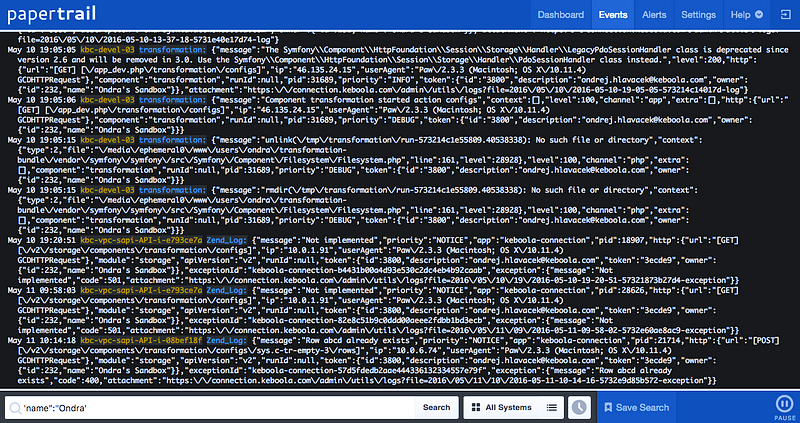
We love logging! It helps us locate bugs, debug unexpected behaviour, monitor hacking attempts. We do not log obsessively everything, but we're receiving the dreaded “Reached $20.00 of additional log data. Log processing will continue.” email from Papertrail quite often. And we log a lot of structured data.
Syslog and logging apps are not made to work with JSON or any other type of structured data, but without it our search based alerts would be really difficult to set up. So we started sending stringified JSON to Papertrail. Search made easy, but it sucked visually.
Do you remember bookmarklets? Those (supposed-to-be) tiny javascript snippets hidden behind a bookmark and when you clicked the bookmark the code executed. So 2000’s. No updates possible, consuming space in your bookmarks bar. And that was our first solution, a bookmarklet that replaced a JSON string with a structured JSON.
Fortunately Martin soon realised the downsides of a bookmarklet and started playing with a Chrome Extension. Packed that code in a .crx file, uploaded to S3, and sent the link to fellow developers. Iteration two, done. Btw, this is a really nice tutorial for writing Chrome Extensions.

Years later, when Chrome 50 sneaked into our laptops, the extension stopped working. Not from Chrome Web Store, they say. You could still drag and drop the .crx file onto the browser, but it lasted only until a restart. Time to fire up the editor and finish him!
I was wondering how the old code would work as an official Chrome extension in Chrome Web Store. Paid $5, zipped the extension files and uploaded to my new developers dashboard. Voila, it's there, flawless!
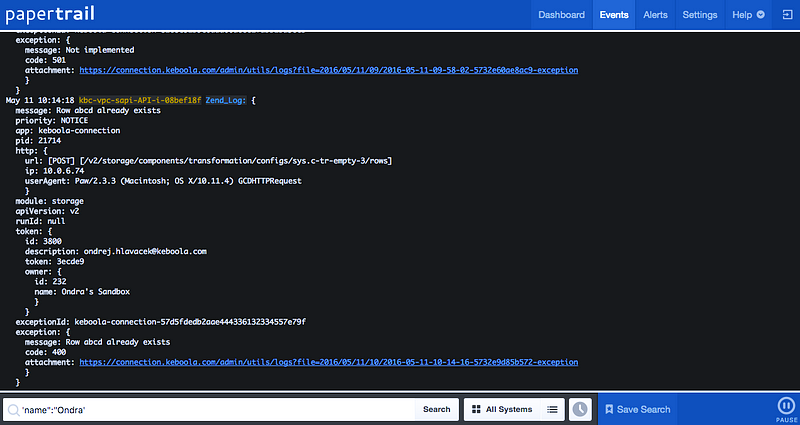
But the work was not done. The original bookmarklet (ahem, extension) relied on listening to papertrail:eventsLoaded event triggered on #event_list element from Papertrail application to parse new incoming records. Don't ask me how I found out this event, there's no official documentation. Probably bit of a luck with an reverse engineering attempt back in the day.
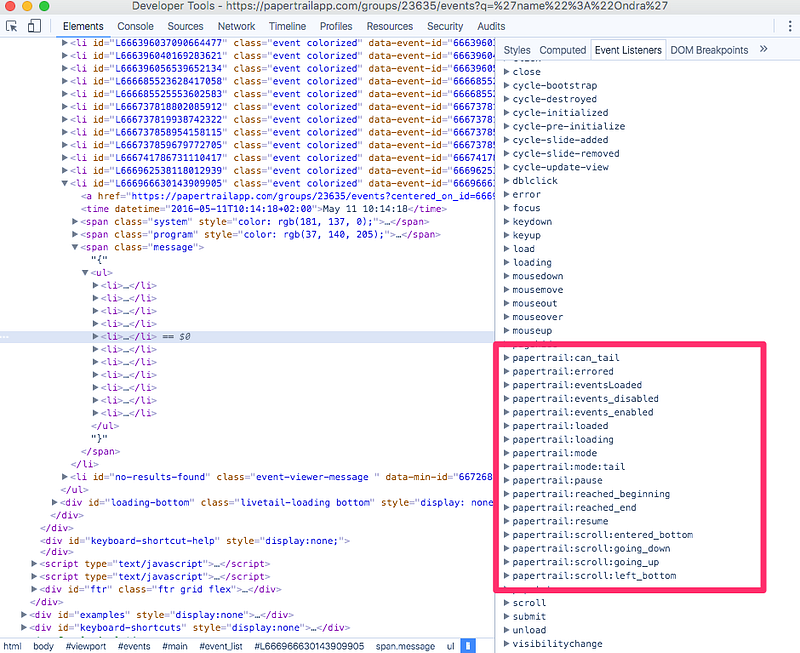
I couldn't wrap my head around it. It worked in previous iteration, binding to the event directly in console worked, the DOM element was accessible from within the extension. I almost went back to using setTimeout and parse the records every second… but then I've started playing with injecting the code directly into the page (which seemed to be able to listen to the event) and found this StackOverflow question. Injecting for the win. I put the script in a separate file and the extension injected the script at the end of the Papertrail page.
(function (window) {
var s = window.document.createElement(‘script’);
// script.js is almost unchanged code of the original bookmarklet
s.src = chrome.extension.getURL(‘script.js’);
s.onload = function() {
this.parentNode.removeChild(this);
};
(document.head || document.documentElement).appendChild(s);
}(window));And that's it, the extension is available in Chrome Web Store and the source code on GitHub.
What next? Automatic build and upload to Chrome Web Store (via Travis), remove the extension icon from the browser, some indentation issues… Any other ideas? Let us know!