How we use Docker
Many people often ask us about how we use Docker. The folks which are not familiar with Docker think that we do some hardcore magic and the…
Many people often ask us about how we use Docker. The folks which are not familiar with Docker think that we do some hardcore magic and the folks already familiar with Docker are surprised what we do with it.
Why?
To understand better what we do, let’s consider this schema of the main Keboola Connection (KBC) ETL process which is composed of:
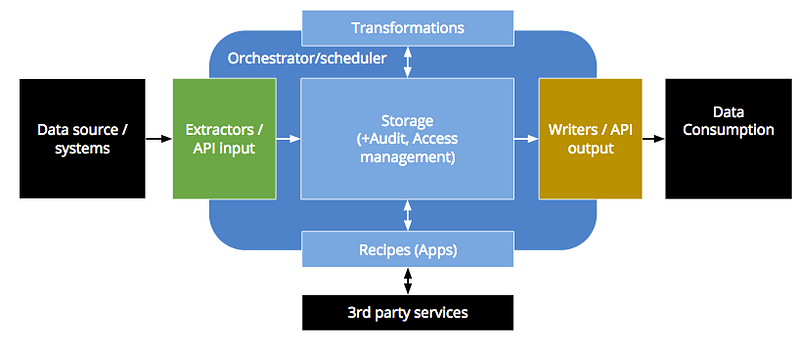
It is important to note that every data transformation (Transformation, Recipe or Application) is a processed as batch job. When a user wants to transform some data, a job (with the supplied transformation code) is created, pushed into a queue. Then a worker which is free takes it and processes it.
For years, there was one and only logical solution for transformations — SQL. Since the data in KBC Storage are already stored in some kind of database (MySQL or Redshift), this is a natural solution.
SQL is a very powerful language, but it is not procedural and some things are really hard to do in it. In the mean time we were receiving requests from our customers for integrating R language, so that they can do their hardcore data science in it. Now comes the difficult task — how to allow an arbitrary user to run his arbitrary code in an arbitrary language. This is an admin nightmare and a thing everyone wants to avoid. Luckily Docker is a perfect solution for this.
Introducing Docker
If you are not familiar with Docker, let me introduce it briefly. Simply said — Docker is a virtualization technology. Unlike the classic virtual machines (which virtualize the PC hardware and run the whole OS in a virtual environment), Docker virtualizes the operating system environment and runs only the applications in a virtual environment. For that, the Docker has two concepts — images and containers. A Docker image is a definition of how the OS should be configured (e.g. what libraries are installed and in which versions) — that definition is stored in Dockerfile. A Docker container is created when you run the image and it is the isolation environment in which an application is executed.
Docker is a based on the principle of layers. This means that images are based on other images, and are generally very small and they load very fast. Docker also has a very aggressive caching system. For example, let’s say, you want to create a dockerized R applications which also require that e.g. git is installed. To create such application, you can take the base R image (which is based on base Ubuntu image), create a new image with installed git, then you can create another image in which you put your application.
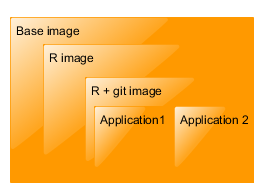
If you run Application 1, its image is built (or downloaded from Docker registry) and run (a container is created). Thanks to the system of layers, if you want to run Application 2, docker only needs to build the Application 2 image. For 20 applications you only need to store those applications (with a little extra overhead), you don’t need to store 20 2+GB virtual machines. This is a killer feature for us.
Second killer feature for us is that Docker image is stateless. When you run an image a new container is created. A container creates a new OS layer in which it executes the image and any changes made on that layer are lost when the container is deleted. No matter what the container does, it cannot break the image. It also means that you can have an image and multiple containers made from that image, each with the same starting position and none of them affecting any other container.
How?
The entire KBC is composed of many components (which can be either extractors, writers, transformations or applications). Some of those components are dockerized (actually we have a total of 158 components and 57 are dockerized (37 on DockerHub, 20 on Quay.io). To easily run dockerized components we have created our own Docker wrapper component. That component defines a universal interface that we use in many places in KBC (and our users know it from R and Python transformations). The Docker wrapper component mainly prepares data for other dockerized components, runs them, and stores the data in storage.
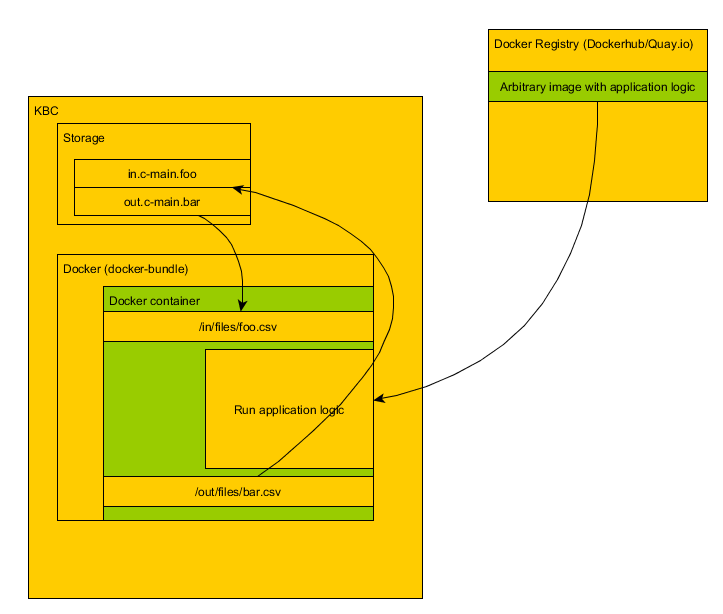
With Docker bundle, we created a nice and clean interface. We let the end-user specify input/output mapping for the component and optional arbitrary configuration. Then the Docker component pulls the required image and injects the input tables (in.c-main.foo) in form of CSV files (foo.csv) into the container. It then runs the container and when the container is finished, it grabs the output CSV files (bar.csv) and pushes them into KBC Storage according to what has been specified in the output mapping configuration (out.c-main.bar). While the container is running, we grab its standard output and redirect it to our Storage events.
This means that the running container is nicely isolated. On the OS level it is isolated by Docker layers itself. On the KBC level it is isolated by Docker bundle — dockerized applications cannot access anything in KBC Storage except for what the end-user has specified when running the component. When a container is finished, we simply delete it. Yes, that means, that whenever a user (or automatic Orchestrator) hits ‘Run’ on an R or Python Transformation, we create a new container in which the transformation is run.
How do we do it technically? I’d say that we took a very simplistic approach. We simply execute the Docker command line client with various options. We have experimented with other clients and libraries, and the command line client has surprisingly proved to be the most stable thing. Using standard command line parameters, we can wrap around a couple of useful features (like limiting memory, network connections, etc.) By using docker login we can work with private Docker images.
When we mastered this, we realized that with this technology, we can integrate virtually any application or API we stumble upon. And then we realized it’s much better to let other people do it.
So we offer our 3rd party application developers two approaches — the release way and the master way. In the master way we always check for the latest version of an image on every run, and if a new version exists, we’ll pull the newer image and use it. This allows 3rd party developers to have fully automated CI. This also increases the pull counter nicely:
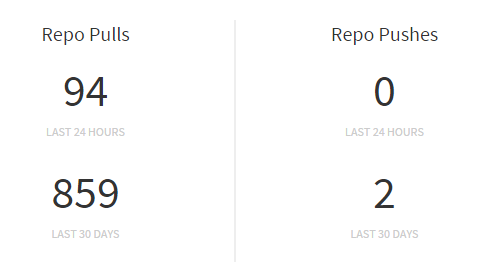
On the release way, we only pull the image once and keep using that until its version tag changes.
Apart from running standard prebuild images, we can also build Docker images on the fly (when they are requested). This is mainly used for Custom Science applications where it saves our 3rd party developers a great deal of time, because they don’t need to maintain their own Docker images and still they can run their code in our environment. What we do is that we build an image dynamically and inject contents of a git repository into it. It may seem like a tremendous overhead, but Docker has very aggressive caching system (Killer feature no. 3), which actually caches every single line of Dockerfile. This means that even if we build an image on the fly, it will finish within a few fractions of seconds if someone had previously used it.
So far, we still use a single m4.2xlarge instance for worker running all Docker jobs. There are some potential issues with running dozens of images on a single server. All our (and most 3rd party) images are based on the same base image, this way we try to share as much as possible which means that the final container overhead is pretty small. We do clean up old containers (in our case a container is never run twice). And also, since the Docker itself is running on a worker server, which contains no data, we simply recreate the server from time to time.
Are we happy with Docker?
I’ve heard this question many times. And I’d say yes we are. We started to adopt Docker in version 1.4 on Dec 19, 2014. I’d say that qualifies us as early adopters. Over that time we have run into multiple issues, and Docker gave us some hard times, but most of those issues are resolved by now. Though our Docker use case may be quite an edge case: we run each container only once; we don’t run any services in Docker; we don’t have any communication between containers; we don’t use Docker Compose; we don’t use Docker Swarm, Kubernetes, Mesos-Marathon or whatever; we do not bother with cleaning up images and we delete all containers as soon as they finish. We simply don’t care.
Future plans
We definitely would like to improve component logging. Currently we use stdout/stderr, which is universal, but not really convenient for the developers (no formatting, no structure). This is not really a question of Docker, more of agreeing on a simple, yet universal interface.
We are also playing with Docker management and monitoring services such as Docker Cloud to utilize servers more efficiently. We would also like to offer application services in docker for those cases where a single asynchronous job is not a good solution. And then we are using Docker more and more for actual development, but that would be a whole other story.