Dogfooding: Papertrail, Snowflake and JSON logs
We're piping a lot of logs into Papertrail. From server logs to application events, everything goes there. The speed, powerful search and…
We're piping a lot of logs into Papertrail. From server logs to application events, everything goes there. The speed, powerful search and notifications are really valuable to us.
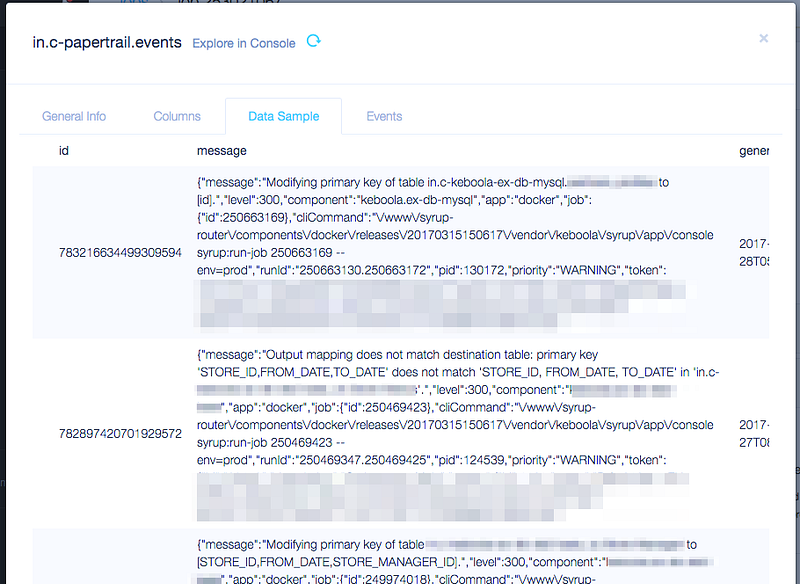
Couple of weeks ago we have noticed a bad pattern in some configurations and application executions — primary key mismatch. Existing tables and their respective configurations didn't have the same primary key settings. Moreover, some of the mismatches were only created at runtime, they were not stored in any config. We had to set up something to monitor, evaluate and help us fix the situation. All our apps send JSON logs to Papertrail, so it was easy to log some further information.
We had it there, we could observe how many mismatches were created, but we had no big picture. I wanted to know how many projects and which tables were affected (one table could be a source of multiple incidents) to start fixing. And we have all relevant data in JSON. Not an easy task for Papertrail.
Records in Papertrail are stored during retention period, all older logs are stored in S3 and available as zip archives via an API. As I didn't have to go back that far (I am at most interested in last couple days), I could rely on the Search API to retrieve logs from my application.
So I used the Generic Extractor Docker image and started developing the config to retrieve the logs locally. Generic Extractor acts as a smart/scriptable HTTP/REST client, that parses JSON responses to a set of CSV files. After a few iterations I had it dialled.{
"parameters": {
"api": {
"baseUrl": "https://papertrailapp.com/api/v1/",
"http": {
"headers": {
"X-Papertrail-Token": {
"attr": "token"
}
}
},
"pagination": {
"method": "response.param",
"responseParam": "min_id",
"queryParam": "max_id",
"includeParams": true
}
},
"config": {
"token": "{MY_TOKEN}",
"jobs": [
{
"endpoint": "events/search.json",
"params": {
"min_time": {
"function": "strtotime",
"args": [
"5 days ago"
]
},
"max_time": {
"function": "strtotime",
"args": [
"now"
]
},
"q": "\"Error deleting primary key of table\" OR \"Modifying primary key of table\" OR \"Error changing primary key of table\""
},
"dataType": "events"
}
]
}
}
}
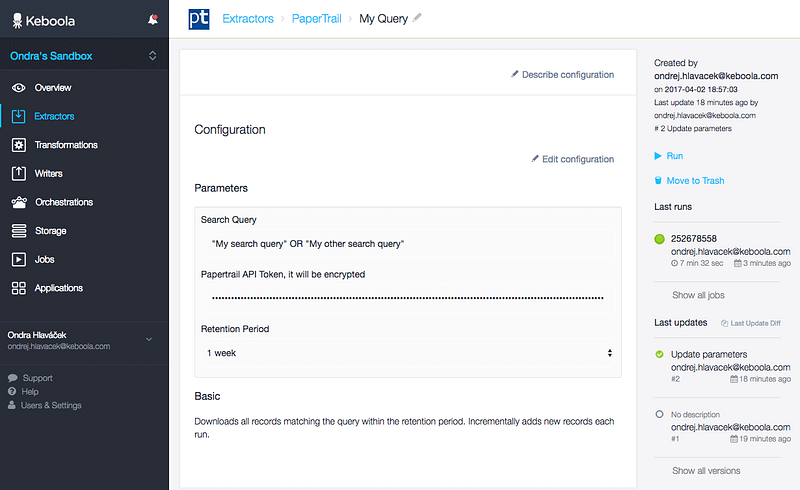
You know what? You can try this yourself! Follow the Local Development guide in Generic Extractor and use this JSON, just change the config.token and config.jobs[0].q attributes. You'll get a CSV file with all matching records within last 5 days.
I used the very same config and put it into my Keboola Connection project and had the data immediately in Storage. Few more tweaks and I had it running every day incrementally.
But the data I was looking for was still in JSON. A piece of cake for Snowflake. After few short queries in Keboola Connection Sandbox I had the queries I needed and added them to the orchestration.CREATE VIEW "repeating_modifications_yesterday" AS
SELECT
PARSE_JSON("message"):"token":"owner":"id"::STRING AS "projectId",
PARSE_JSON("message"):"token":"owner":"name"::STRING AS "projectName",
SUBSTRING(
SPLIT_PART(PARSE_JSON("message"):"message", ' to ', 1),
32
) AS "table",
COUNT("message") AS "count"FROM "events"
WHERE
TO_DATE("generated_at", 'YYYY-MM-DD"T"HH24:MI:SSTZH:TZM') = DATEADD(DAY, -1, CURRENT_DATE())
AND PARSE_JSON("message"):"message"::STRING LIKE 'Modifying primary key of table%'
GROUP BY 1, 2, 3
HAVING "count" > 1
ORDER BY "projectId"::NUMBER ASC, COUNT("message") DESC
;
I have created a table for each report I needed and I have them ready with the morning coffee.
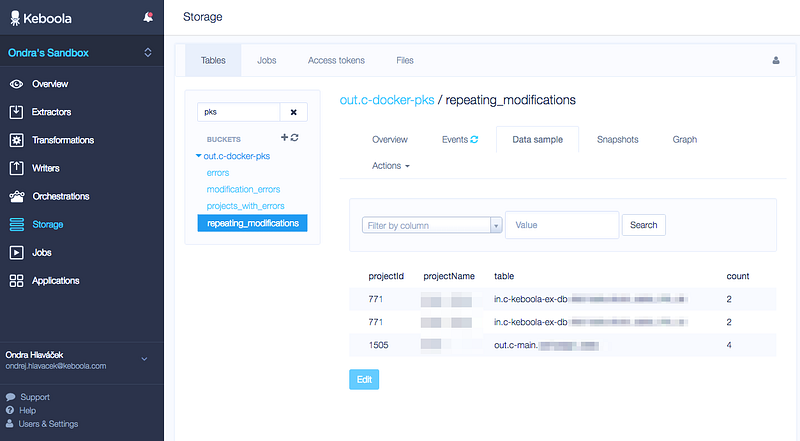
I could have it easily delivered to my Dropbox, Google Drive or something else, but this is more than enough for me to start getting in touch with customers to resolve this issue with them.
And as a bonus, I have wrapped up my Generic Extractor configuration into a separate component. Papertrail extractor is now available in every Keboola Connection project.
And if you don't have one, you can build your own open-source Generic Extractor Docker image and incorporate it into your own pipeline.