Custom coding standard - why and how
When I joined Keboola a few years ago, there already has been a PHPCS standard set up. Most of our projects were using PSR-2. One would…
When I joined Keboola a few years ago, there was already a PHPCS standard set up. Most of our projects were using PSR-2. One would probably wonder what led me to create a new custom PHPCS standard when one was already in place. It may even seem senseless and wasteful. In this article, I aim to explain to you why it actually makes sense and saves time and money in the long run.
The why
Around the same time I joined the team, the pull request (PR) reviews transitioned from encouraged to mandatory. Also, there were some new hires.
However, it later became obvious that the PSR-2 which was being used at that time had some shortcomings. PSR-2 has been created by consensus of many different projects and is in itself a result of compromise. And it shows, mostly in its vagueness. It does not go into detail, but specifies only the bare minimum you should do.
With the mandatory reviews and new hires this became a problem. Some portions of the reviews focused on cosmetic issues in the code and the different ways people perceived what readable code meant. Some of us were used to Yoda conditions, assignments in conditions, using double quotes everywhere, etc., while others found one or the other unreadable or even plain harmful.
Sometimes, this caused the PRs to stall for a long time due to discussions like the one below.
A: I noticed you use assignment in condition here. Shouldn’t that be outside of the condition?
B: It’s totally fine.
C: I thought we said we won’t be doing it anymore.
B: Did we? Where?
C: Dunno, let me check. … Sorry, can’t find it now.
A: Anyway I think it’s not a good practice because —
B: This is silly. We’re doing hairsplitting while this PR needs to ship ASAP. Let’s postpone it for now.
A: No problem. I just thought I should flag this.
While there is no ill will behind such discussions, they have a tendency to become repetitive and heated. Soon, it became obvious that we needed to solve this in a more structured way than through comments in random PRs. And that’s where custom PHPCS standard comes into play.
To sum up, we implemented custom coding standard because we wanted to (1) to formalize the discussions that take place organically and (2) defuse the heated arguments.
The how
There are two general ways to implement a strict coding standard.
The first is what I call “big bang”. That means you search for a strict coding standard — you will probably find something very opinionated like Consistence CS — and you shove it down the throat of your fellow developers. To say this tends not to work is an understatement. There is a technical as well as social issue with it. The technical issue is that if you run it on your current codebase, it will spit gazillion non-fixable violations and you will have to spend weeks or months excluding or fixing the offending pieces of code. The social aspect is that it will be perceived as something “they/you” did as opposed to something “we” did. And that is a bad way to get people on board with anything.
The other way is what I call “tiptoeing”. With this way, you find a standard that mostly fits your current codebase and your whole team can agree upon with little to no discussion. That was our case with PSR-2 that was already adopted and accepted. If your code is extremely inconsistent, you can start with the actual bare minimum — settle on line endings and tabs-vs-spaces — or whatever else you feel is the bare minimum.
Next, start using the bare minimum and disallow any code to get to production if it does not pass. For us, this was already done and most of our builds were using PSR-2 and would fail if the code did not adhere to it. If you, like us, have many different projects in multiple repositories, it makes sense to create a dedicated package for your coding standard that will be updated and installed in a predictable way. We created keboola/phpcs-standard for this purpose.
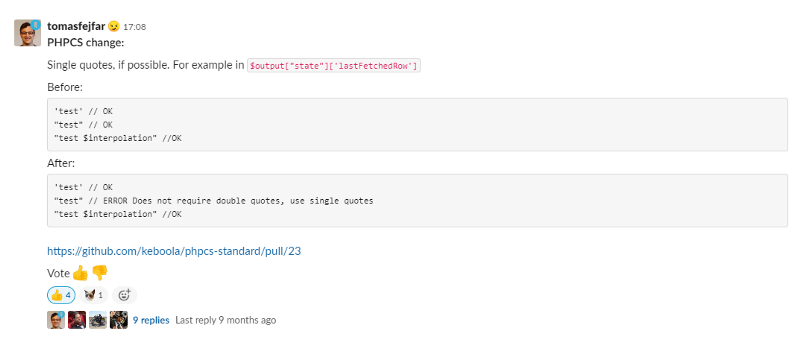
Now you’re ready to start building your custom standard from the ground up. Whenever there is a discussion regarding some styling, it’s time to settle it once and for all. What we did is that we created a Slack channel, #best-practices, that is used for such discussions. Below, you can see one such message discussing disallowing double quotes.
As you can see, a PR is attached to the message (you can see it live on Github). You can also see a discussion about it and that the votes are overwhelmingly in favor of the change. When the change is merged, it’s released and every new project starts using it. Also, when our core projects get updated, it’s typical that we upgrade the coding standard package and fix any issues.
And that’s it!
#fails
As always, there are some downsides to this approach.
Keeping many repositories up to date
The new standard’s main disadvantage is that it is dynamic in nature and therefore incurs some maintenance costs. Especially in our case with more than 500 repositories on Github. It’s not practical to keep all the repositories on the latest version of coding standard. So what we do is that we always start a new project on the latest repository and update and fix issues when we get back to it after some time. We only keep the busiest repositories updated. So far we have had no problems with this approach. Also our use-case is not very typical, so this may not be a problem in your case.
Lack of Completeness
I was hoping for a stricter and more rigorous coding standard, which didn’t happen. But I’m not the company myself. Having everyone aboard is much more important. So, this is not really a bug, but rather a feature. :)
#wins
Universal adoption
As everyone is somewhat invested in the coding standard’s creation, it has almost universal adoption across our codebase. So far, I have not regretted creating it and I’m happy with how it has turned out.
Improved PR flow
In my opinion, it has also improved the PR workflow. Now we hardly ever see any discussion regarding the code cosmetics. Most discussions are now about architectural or business issues.
Legacy codebase usage
Even our most legacy code is using the standard. We fixed the issues one by one, step by step, each rule violation in its own PR. Some were fixed automatically by phpcbf. Some needed to be fixed manually. We ignored some rules where fixing manually would be too much work.