cp in Docker: Cannot allocate memory
Once in a while we encounter a simple cp or gzip command in Docker with a mysterious Cannot allocate memory error. Sometimes the error is…
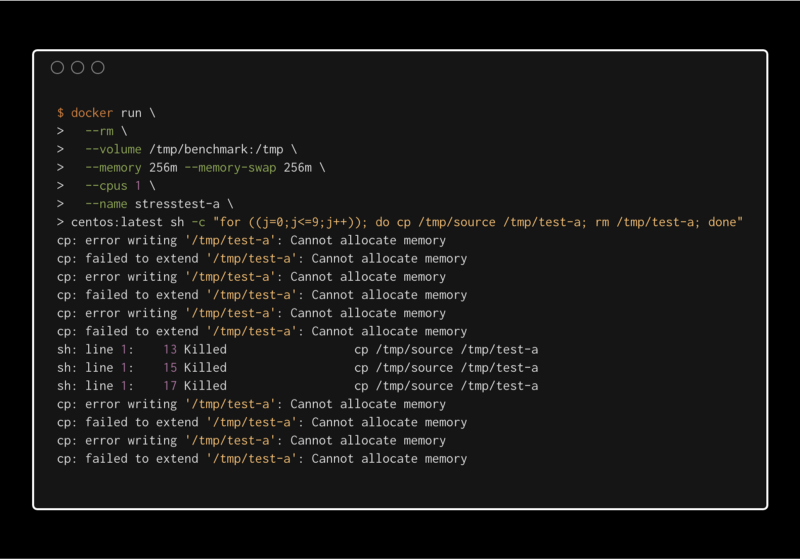
Once in a while we encounter a simple cp or gzip command in Docker with a mysterious Cannot allocate memory error. Sometimes the error is hidden under a cryptic message (cURL error 23: Failed writing body (6702 != 16384)). After restarting the container, the command finishes successfully. For months I had no idea why this was happening, and I was blindly adding more memory to the affected container. But does it make any sense to have --memory 512m for an Alpine Linux container that only runs the cp command?
Going through instance logs and monitoring, a pattern started emerging. This had something to do with high IO loads on the host at the moment of failure. So a long struggle has begun.
(Not a) Solution 1: Changing disk type
Our infrastructure is on AWS, the affected instances had two 1TB EBS volumes gp2 in RAID 0. The EBS IOPS setting in the AWS console was already maxed out to 3,000 so I tried changing the disk type to st1. Even though the st1 disk type should have provided superior performance for our use case(heavy IO), the error rate immediately went up, so I had to change back to gp2 asap.
(Not a) Solution 2: Limiting IO in Docker
I dug into Docker settings and discovered new command line options --device-write-bps and --device-write-iops (and their read counterparts). Eureka! I was waiting for this for quite a long time. A simple test with dd showed that the limits worked. Off to production, problem solved.
After a couple of weeks, the errors were back. They probably didn't go away at all, we were just lucky that the instances had enough IO power to keep them down. I had to start questioning all I knew and thought. I had to figure out a failing test scenario and then find a solution.
Intermezzo: Test case
After a bit of tweaking, I was able to reproduce the error myself. On a weaker machine with slower disks three Docker containers, running a sequence of a few cp commands, finally showed the dreaded Cannot allocate memory error message on request.
First I figured out that device limiting did not really affect our use case. The cp and other command line commands do not respect the IO limits set to the container. They just use all IO the host instance has. The only case the limits are in effect is the dd oflag=direct command (dieselgate anyone?). For more info read Pavel Trukhanov's Medium post and moby/moby#16238.
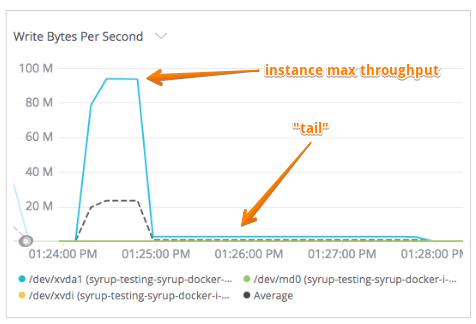
Furthermore, setting throughput and IOPS limits to Docker containers seemed to cause a very weird behavior with heavy IO containers. The IO peaked at the instance's max and after doing all the IO work (cp command finished), the IO stalled at very low numbers. It almost looked like it sort of waited so that the average IOPS/throughput matched the limit. And during the “tail” period, I was not able to kill the running container, run another docker command or even restart the dockerd daemon. The system had been busted until something decided to let go and all commands were responsive again.
So I was back to square one with containers falling on my head every week.
(Not a) Solution 3: Filesystem, Raid
Long story short. No difference between XFS and EXT4. Switching off RAID completely, using a different mount or not mounting a volume to the Docker container did not help either.
(Maybe a) Solution 4: Swap
In a discussion, someone mentioned swap. So I started playing with swapon and swapoff commands and their settings. No result here either. But I remembered that we intentionally did not use swap memory for Docker containers. One of the containers we used to write to Elasticsearch had issues with swap memory, so we turned it off and observed no errors.
I was desperate, so I thought I'd give it a try. Like a miracle, adding as little as 1 MB of swap memory (--memory=256m --memory-swap=257m) made the problem completely go away in my test case.
As a result we removed the --memory-swap option completely and use the Docker default now:
If--memory-swapis unset, and--memoryis set, the container can use twice as much swap as the--memorysetting, if the host container has swap memory configured. For instance, if--memory="300m"and--memory-swapis not set, the container can use 300m of memory and 600m of swap.
We're only a few days in with this solution deployed, so we're still not sure about the results. The test case was successful, but we'll yet have to see what the production environment has to say. But this is my last hope.
Call for help
If you made it this far, let me know what you think. I am no Linux expert, so I may have been approaching the problem in a wrong way. Any suggestions might help me to tackle similar problems in the future. Thanks!