cp in Docker: Cannot allocate memory, part 2
This is a sequel to a previously published post, https://500.keboola.com/cp-in-docker-cannot-allocate-memory-1a5f57113dc4.
This is a sequel to a previously published post, https://500.keboola.com/cp-in-docker-cannot-allocate-memory-1a5f57113dc4.
tl;dr version
Look at dirty_* parameters of the Linux virtual memory subsystem.
Long version
When we reintroduced and increased swap memory for the Docker containers, the issue with simple shell commands running out of memory disappeared. But only for a while. It came back and even containers with --memory=1024m started to fail occasionally (and they use another 1 GB of swap).
Hardly a cause for alarm, it was a rare issue, affecting roughly one job per month (one out of ~1 million). However, its circumstances were interesting. Two of the failed jobs happened
- while running the same configuration, each a month apart,
- on different worker servers, and
- at roughly the same time (1 a.m.).
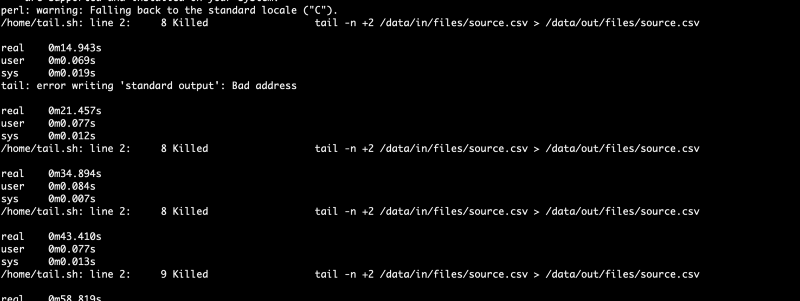
This job failed when shaving off the first line of a 100 GB CSV using the tail command in an alpine Docker container. The container was terminated with OOMKilled: true (via docker inspect). For a simple task with ample memory (1 GB memory and additional 1 GB swap), this should not be a problem. We were back at square one.
Setting out to reproduce the failure, I have opted to use parallel this time and ran a few containers simultaneously. Soon enough, I had them failing — 5 containers, each with --memory=128. Running tail on a random 2 GB file was enough for it to act up.
This is a list of things I tried and benchmarked, all without any success:
- Amazon Linux 2 AMI
- Different versions of Docker
- Not executing
tailon a mounted folder - Limiting Docker IO
- Mounting a different folder from the host
- Other Linux distributions (both as the host and the container)
- Using instance store instead of EBS and storage optimized instances
- All of the Docker container limiting options
- Instances outside of AWS
The only thing that seemed to help, was to avoid Docker and run the tail command directly. But this was a no-go, and we had very good reasons to run even simple commands in Docker.
Luckily I got a fresh pair of eyes to look at the issue. Vojta, who just recently returned from a bike trip to Magadan, was a bit better with Linux and started poking into it with me. He traced the processes and found out what I suspected the whole time, but could not find the proof. The write operations did indeed consume memory and when they consumed more than the limit assigned to the Docker container, the processes were killed. The question now was why they consumed memory and how to limit it.
Long story short, after a bit of googling he found https://lonesysadmin.net/2013/12/22/better-linux-disk-caching-performance-vm-dirty_ratio/ and we started playing with the vm.dirty_* parameters.
We needed to keep the dirty memory lower than the container's total memory limit, so using *-ratio parameters was out of question. We use a variety of instances, so even setting it to the lowest possible value (vm.dirty_ratio=1, which is 1% of the total memory) could not be enough to keep some of the tiny containers safe.
We resorted to using the parameters with absolute values, tried several configurations, benchmarked them, and as I write this post, we're rolling out instances with these settings:
# size of system memory that can be filled with “dirty” pages — memory pages that still need to be written to disk — before the pdflush/flush/kdmflush background processes kick in to write it to disk
sysctl -w vm.dirty_background_bytes=134217728
# the absolute maximum amount of system memory that can be filled with dirty pages before everything must get committed to disk
sysctl -w vm.dirty_bytes=268435456I was not able to reproduce the failure with the above settings no matter how hard I tried. 50 containers, each with 64 MB memory, were executed without problem. In the previous scenario, all of them would have failed. I spent a great deal of time trying to get the error appear but luckily without success.
There is no more science to these values than a few random picks and benchmarks. Also, we wanted to set the values as low as possible to keep even the tiniest containers relatively safe (our smallest containers can have lower than 256 MB memory). As another precaution, we'll be increasing memory limits to the smallest containers to be above these two values.
I'll keep an eye on this for a few days if these parameters affect any other behavior but so far it looks very promising.
You can see the source code of the benchmark/test on GitHub.