Best Practices for Azure DevOps (Release) Pipelines
As a part of our Azure adoption, we're also trying out Azure DevOps. Our current CI/ CD pipelines run almost exclusively on Travis CI. We…
As a part of our Azure adoption, we're also trying out Azure DevOps. Our current CI/ CD pipelines run almost exclusively on Travis CI. We didn’t want to start rewriting the existing code, so we decided to append Azure DevOps to the existing processes and only use them for the new, Azure related stuff. Out of the five DevOps offerings (Boards, Repos, Pipelines, Test plans, and Artifacts), we’re only using Release Pipelines to deploy and update the application and its Azure infrastructure. The rest of the CI/CD process remains intact so far.
There are two kinds of pipelines in Azure DevOps — Build and Release. Two main differences (as I perceive them) between them are definitions and triggers.
Definitions — Build Pipelines are defined and stored in YAML, and can (most likely) be stored in the repository along with the application code (like Travis CI). Release Pipelines, on the other hand, can only be defined in the Azure Devops UI. They can be exported to JSON (and imported back), but that's as far as their “pipeline-as-a-code” approach goes. Things are likely to change, so I'm not worried about it right now, but it would be nice to have the definition along with the code and be able to update the Release Pipeline with a commit in a repository.
Triggers — Build and Release definitions have a different set of triggers. The main difference for us is the Azure Container Registry trigger, which is only available in Release Pipelines. (I am actually taking a shortcut here; it should be theoretically possible to trigger a Build Pipeline from ACR using this undocumented feature, but I wasn't successful in making it work.)
During the months spent in Release Pipelines DevOps, we came up with a few tips we'd like to share with you.
Scripts first
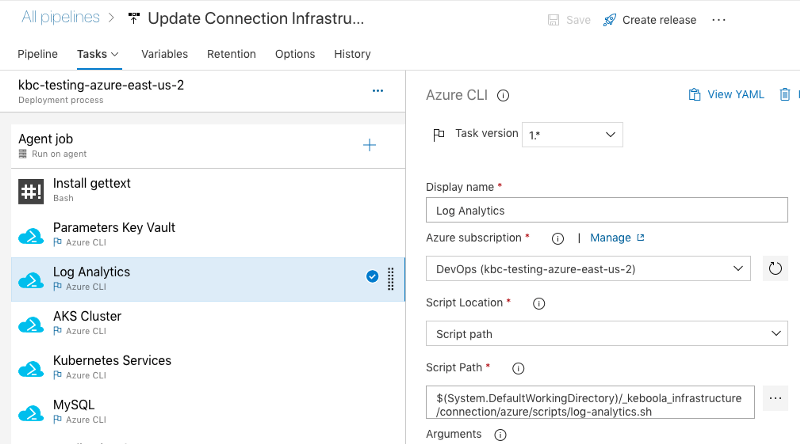
We develop all parts of the Release Pipeline as small Bash scripts that accept “arguments” in the form of ENV variables. The Release Pipeline then consists of a series of Bash, Azure CLI and AWS CLI tasks. We can easily run these scripts locally or in a different CI/CD tool. We try to keep these scripts small; that makes debugging easier. Plus we can run only some of them in certain scenarios.
Infrastructure as a code
ARM templates are a great way to define Azure infrastructure (again with some exceptions like Active Directory and some networking stuff) and we use them to create and update infrastructure parts of the application. The infrastructure definition stays in our codebase and we use Azure CLI tasks to deploy it.
az group deployment create \
--name connection-mysql \
--resource-group $RESOURCE_GROUP \
--template-file ./connection/azure/resources/mysql-db.json \
--parameters keboolaStack=$KEBOOLA_STACK \
administratorLogin=keboola \
administratorLoginPassword=$PASSWORD \
aksClusterVnetName=$VNET \
aksNodeResourceGroup=$NODE_RG \
skuName=$MYSQL_SKU_NAME \
skuSizeMB=$MYSQL_SKU_SIZE_MB\
backupRetentionDays=7Do not use (overly) specialized tasks
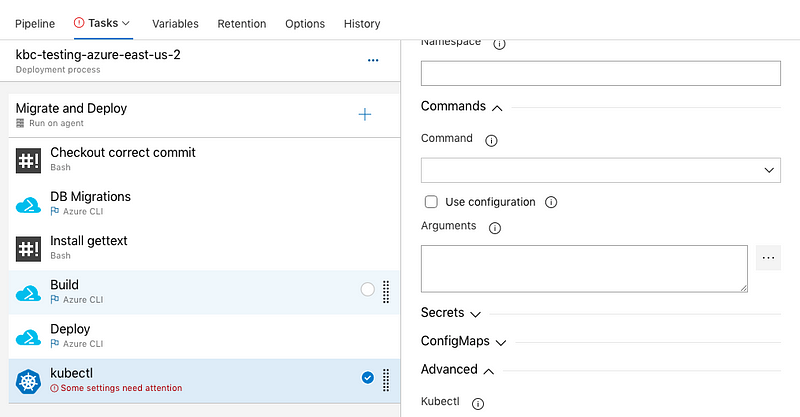
They are simple, and good for a PoC, but that’s it. Complex operations, debugging, passing variables, parametrization or execution control are almost impossible. You have to hardcode resource names directly into the task, which makes change management impossible. We tried the Kubectl task, but after a short while we have turned that into simple Bash scripts running kubectl commands manually, which gave us so much more control.
kubectl apply -f ./provisioning/kubernetes/deploy/connection-api.yaml
kubectl rollout status deployment/connection-api --timeout=900sThis Bash script is so much easier to understand than two Kubectl tasks with dozens of input fields in DevOps. The deploy process definition also stays close to your code.
Use dynamic resource names and IDs
Except for ARM Template Deployment names. We assume that each instance of our application (e.g. a region) lives in a separate subscription. Unique name requirements vary greatly among resources — some must be unique within the whole Azure platform, while some only have to be unique within a single region in a single subscription. We ended up suffixing all resource names with hashed strings containing a stack name, region and few other variables to satisfy the uniqueness constraints. Thanks to that it’s, quite difficult to identify resources for a given instance. To avoid confusion (at least the programmatic kind) we've embraced ARM Template Deployments in Azure and now store all required names and IDs in the deployment outputs. Using Azure CLI, you can easily extract a required variable value from an existing deployment. These scripts typically have very few arguments.
{
...
"variables": {
"clusterName": "[concat('connection-', uniqueString(parameters('keboolaStack')))]"
},
...
"outputs": {
"clusterName": {
"type": "string",
"value": "[variables('clusterName')]"
}
}
}The above snippet from the ARM template stores the variable in the Template Deployment output.
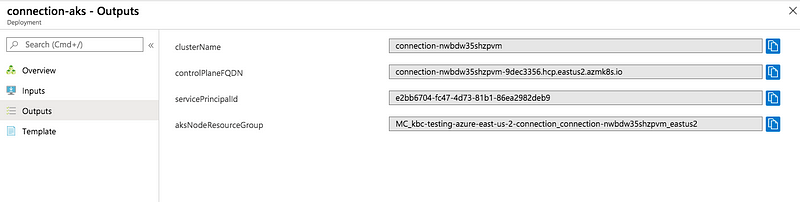
From there, it can be obtained and used further down in any other script.
CLUSTER_NAME=`az group deployment show \
--resource-group $RESOURCE_GROUP \
--name connection-aks \
--query "properties.outputs.clusterName.value" \
--output tsv`If this is a part of a larger script, it has only one argument, RESOURCE_GROUP, and all other variables are dynamically read from their deployments or resources.
Variables are great, but one way only
Pipeline variables map directly to ENV variables in Bash, so the ACR Name variable is available as ACR_NAME env. We use variables to configure the application and its parameters (e. g., nodes count and database size) but never to store any state. Another huge benefit of variables is that they can store different values for each stage.
Though it’s possible for a Pipeline task to write to a variable, it's quite difficult and we've never done it successfully. If you need to store something for later use, use appropriate resources — like Key Vault for passwords and other secrets and Template Deployment outputs for names of resources, or use Azure CLI to obtain the values directly from the resources when required. Subnet ID is a bad variable, number of nodes of an Azure Kubernetes Service Node Pool is a good variable.
Do not store secrets in Pipeline Variables
Use Key Vaults. It’s easy to operate from within Azure CLI.
AZURE_RESOURCE_GROUP=myAzureResourceGroup
AZURE_KEY_VAULT_NAME=$(az group deployment show \
--name myKeyVaultDeployment \
--resource-group $AZURE_RESOURCE_GROUP \
--query "properties.outputs.myKeyVault.value" \
--output tsv \
)
az keyvault secret set \
--name mySecret \
--vault-name $AZURE_KEY_VAULT_NAME \
--value "my secret value"The above script obtains a Key Vault name from a deployment and stores a secret in it. Retrieving secret values is very similar.
az keyvault secret show \
--name mySecret \
--vault-name $AZURE_KEY_VAULT_NAME \
--query value \
--output tsvEvolve the toolkit
While Bash scripts and ARM templates can take us a long way, we need to be aware of their limitations and start thinking about expanding our toolbox. Some situations will require using Terraform for infrastructure or a proper programming language to handle deployment of our app. Currently, we still stick to Bash and ARM templates, but we know they won't be there forever. Something will replace them sooner or later.
What's next?
We start with baby steps and deploy working Release Pipelines as soon as possible to make our lives easier. But we have a long road ahead of us. So where are we heading?
- YAML — Store the Release Pipeline as code within the repository.
- Scaling up — Currently we have only two stages (testing and production), but we'll soon need to have expand this to many production environments. Our nightmare is having to set up each new environment manually. This has to be automated somehow.
- Organization — We've piled up all Release Pipelines randomly across two projects, one called Dev and the other Prod (ahem). We're not focused on making sense of it right now, but we'll need to do that soon.
- Safe development — How do we change the Release Pipeline without possibly breaking production? What measures do we need to take to achieve that?
- Governance — Who can have access, and where? This is a wide topic spanning from our developers to our customers' subscriptions and Azure DevOps in between. Everyone has to feel safe.
What about you?
What are your best practices for using Azure DevOps? What is the single piece of advice you wish you had known from day one? What's your biggest headache? Are we wrong? Share with us; we're here to learn! Thanks.