From Push to Pull: Our Journey to GitOps with Argo CD
This year, we embarked on a journey to transition Keboola’s deployment model from a push-based to a pull-based approach, guided by GitOps principles.
Our goal was to establish a unified deployment process that works seamlessly across multiple clouds and environments. Additionally, adopting GitOps allows us to standardize deployments across teams, eliminating the need for each team to develop their own opinionated way of deploying services. Along the way, we discovered that our unique use case—managing deployments across 20 different environments—is not exactly how GitOps is typically envisioned (or at least commonly implemented). This makes our experience worth sharing, as we continue to navigate the challenges and solutions of this transformation.

The Why
Keboola consists of approximately 20 distinct services. Each service resides in its own repository that contains everything: the application code itself, code for deploying the service (e.g., Kubernetes manifests), and code for provisioning the necessary cloud resources (e.g., queues, databases, etc.).
Since Keboola runs on all three major cloud providers—each adopted at different times—there are typically three different deployment methods for each service. For AWS, infrastructure is defined in CloudFormation; for Azure, it’s ARM templates; and for GCP, we use Terraform. Application manifests vary as well: on AWS and Azure, they are plain Kubernetes YAMLs, while on GCP, they are defined as Terraform resources (yes, we deploy Kubernetes manifests through Terraform). Each method is wrapped in Bash scripts and configured using a large YAML file containing all the necessary values (and secrets) for each deployment environment.
With around 20 environments, this setup translates to approximately 400 individual deployment pipelines. We rely on Azure DevOps for deployments, specifically its release pipelines, which can only be configured manually through the UI. When deploying a new Keboola instance, we must manually add it to each service’s deployment pipeline—20 pipelines in total. These pipelines are cumbersome to duplicate; the process is tedious and error-prone; and if something is accidentally deleted (e.g., an entire stage), it’s gone for good.
It became clear that we needed a unified deployment approach for both services and infrastructure—one that would be scalable, more secure, and easily maintainable.
The What
Enter Argo CD and Helm
We chose Argo CD and Helm for our GitOps setup not only because we had prior experience with them but also because they fit our needs perfectly.
Why Argo CD?
Argo CD offers an intuitive UI that allows anyone on our engineering team to monitor the cluster’s state without requiring direct access to it. In our opinion, it is the most mature GitOps tool available, and its ease of setup allowed us to get started quickly and iterate effectively.
Why Helm?
For us, Helm serves purely as a templating tool; we don’t package or version Helm charts. While Kubernetes manifests for our services remain consistent across all cloud providers, their configurations differ significantly for each Keboola instance. Using a Helm values file to generate templated manifests is the simplest and most efficient way to deploy services across 20 different environments.
Managing Secrets
To manage secrets, we leverage the helm-secret plugin. This involves creating another Helm values file encrypted with SOPS and a KMS key. Argo CD has the necessary decryption permissions, allowing it to use the encrypted values file just like any other values file. Since the file is stored in Git, it benefits from all the usual advantages—diffs, blame tracking, and auditable history.
The How
Centralizing Deployments with a Hub-and-Spoke Topology
We chose a hub-and-spoke topology for our Argo CD deployment. This approach requires managing only one Argo CD instance, with a single set of credentials in one location, rather than deploying 20 separate instances—one for each stack. To support this setup, we created a dedicated infrastructure pipeline that provisions its own Kubernetes cluster, networking, and other resources. Within this pipeline, Argo CD is deployed as a Helm release, preconfigured with ApplicationSets to manage itself (i.e., it is treated as an Argo application) and Keboola services (i.e., specifying what to deploy and where).
From this single Argo CD instance, we aim to manage all clusters where Keboola is deployed. However, we set a requirement to keep all Kubernetes control planes private, which introduced some challenges. Fortunately, running our Argo CD instance on GCP allowed us to leverage Connect Gateway, enabling secure access to private Kubernetes clusters (not limited to GKE) without complex networking configurations.
Refactoring Service Management
Refactoring Keboola’s services was the next step. We essentially split them into three components, a decision that remains a point of contention within our engineering team:
- Application Code: Remains in the original repositories.
- Infrastructure Code: Moved to a centralized infrastructure repository.
- Deployment Manifests: Moved to a dedicated repository, serving as the source of truth for Argo CD.
This separation means that a single change may require three different pull requests across these repositories. However, it enhances observability and enforces a logical workflow:
- Provision the infrastructure.
- Develop and test the application.
- Update deployment manifests to integrate the two.
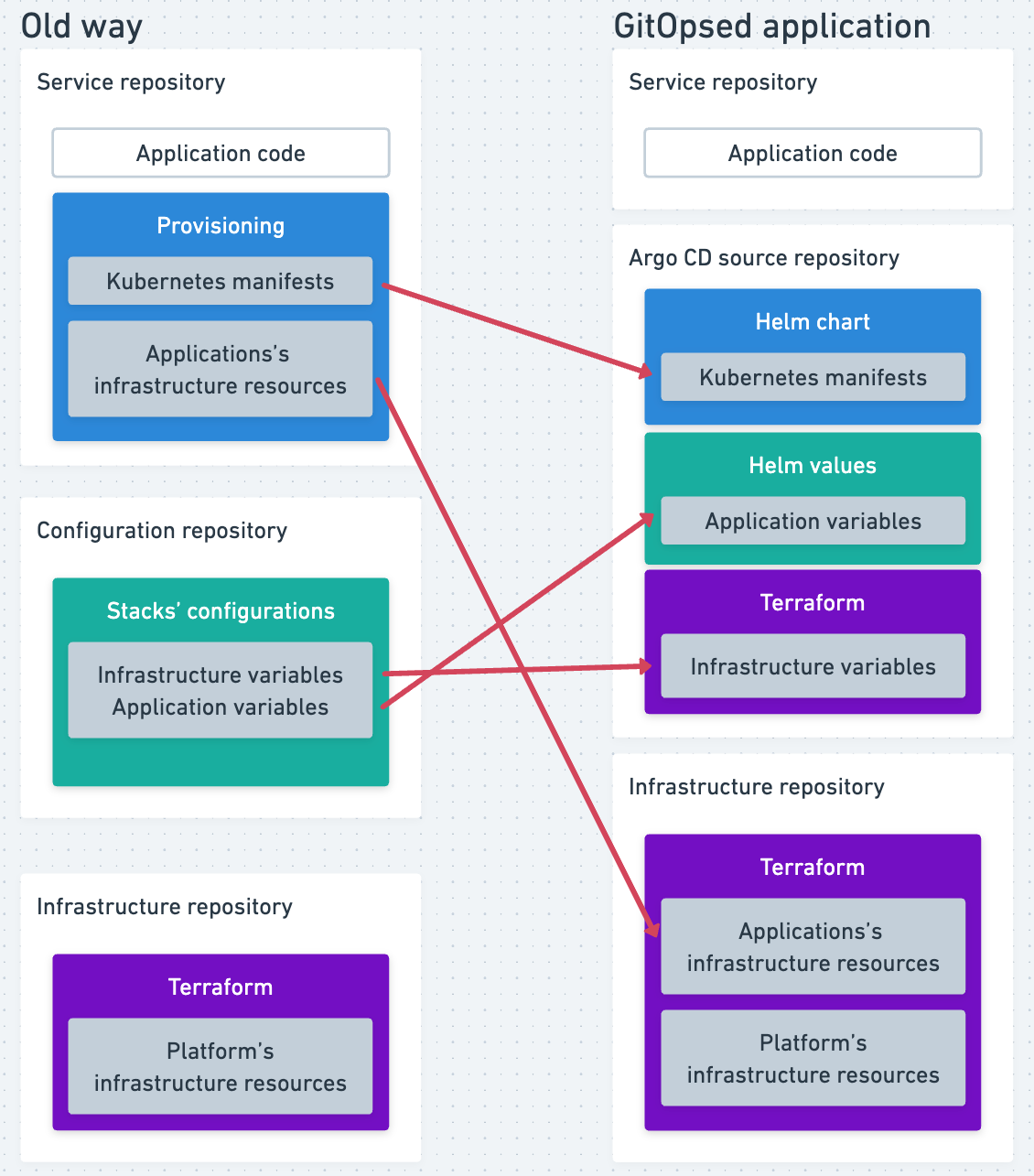
We applied these changes across all services:
- We migrated Kubernetes manifests from Terraform resources to Helm chart templates (i.e., YAMLs).
- We converted Terraform variables used in the old manifests into Helm values files.
We centralized the infrastructure code in the infrastructure repository, with each service assigned its own Terraform module. Using Terraform import blocks, we migrated existing resources with minimal disruption.
To simplify and modernize authentication, we replaced GCP Service Accounts linked to Workload Identity with direct Workload Identity Federation. This required importing and restructuring legacy Workload Identity configurations, including memberships, to ensure clean removal after successful migration.
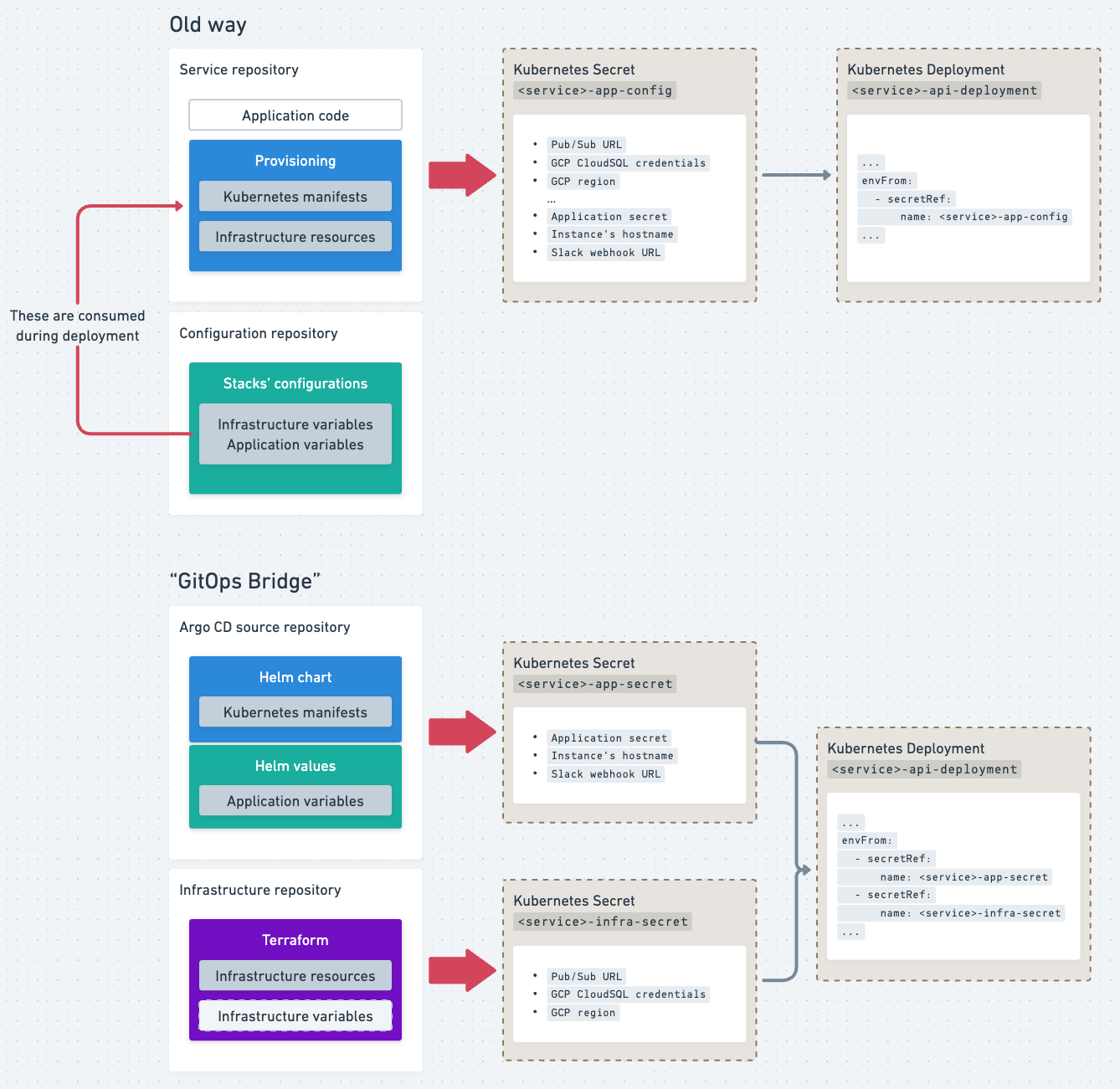
Similarly, we reworked how secrets are managed. Previously, all provisioning data—including application configurations, token secrets, and cloud resource identifiers (e.g., MySQL URLs, credentials, Pub/Sub links)—was packed into a single Kubernetes secret. In the new setup:
- Infrastructure secrets are managed by Terraform, creating a Kubernetes secret for each stack with all necessary infrastructure details.
- Application secrets are managed via Helm values and provisioned through Argo CD.
We then mounted these as two separate secrets instead of one. This approach simplifies management while maintaining compatibility.
Automating Application Reloads on Secret or ConfigMap Changes
How do you reload your Argo CD application if there’s a change in a secret or ConfigMap, without relying on third-party tools like Reloader? We implemented a simple solution: calculate a hash of the relevant secret and annotate all deployments consuming it with the hash. This ensures that pods are restarted only when the annotated secret changes.
For straightforward use cases with a single value of interest, you can avoid unnecessary pod restarts by calculating a hash like this:
apiVersion: apps/v1
kind: Deployment
...
spec:
template:
metadata:
annotations:
secret-hash: {{ .Values.secretKey | sha256sum | trunc 63 | trimSuffix "\n" }}For more complex scenarios, such as hashing the entire secret, you can define a reusable template in your Helm chart. For example, in _helpers.tpl:
{{- define "app.secretData" -}}
APP_ENV: {{ "prod" | b64enc }}
ANOTHER_ENV: {{ .Values.someBoolean | toString | b64enc }}
...
{{- end -}}
{{- define "app.secretHash" -}}
{{- $secret := include "app.secretData" . | fromYaml -}}
{{- $secretString := $secret | toJson -}}
{{- $secretHash := $secretString | sha256sum -}}
{{- $secretHash | trunc 63 | trimSuffix "\n" -}}
{{- end -}}You can then reference this template in the deployment’s annotations:
secret-hash: {{ include "app.secretHash" . }}Finally, iterate over the data in the actual secret manifest:
apiVersion: v1
kind: Secret
...
data:
{{- range $key, $value := (include "app.secretData" . | fromYaml) }}
{{ $key }}: {{ $value }}
{{- end }}This method ensures that deployments are updated automatically when a secret changes, without introducing external dependencies.
Putting It All Together
At this point, we have all the essential components:
- Argo CD to manage clusters and deployments
- Infrastructure pipeline to provision cloud resources via Terraform
- Applications defined as Helm charts, with environment-specific Helm values files
Deploying a New Application Version
In our previous push-based pipelines, everything—including application deployments—was managed within the application repository using Terraform. When a new image was built, Terraform would consume the updated tag as a variable and attempt to apply changes, including updating Kubernetes manifests. While Terraform does not reapply unchanged infrastructure, invoking it for deployments still requires fetching the state, comparing configurations, and determining any necessary updates. This process adds unnecessary overhead when the goal is simply to update a Kubernetes deployment with a new image.
By splitting provisioning into smaller chunks, we now update only what’s needed—such as the Helm chart when there’s an application change. To facilitate this, we introduced a tag.yaml file, a Helm values file dedicated to the application’s image tag. It complements the main Helm values file, which contains other configurations like environment variables or replica counts.
Our custom tooling—a lightweight Python app—automates the entire continuous delivery process by:
- Updating the tag.yaml with the new image tag
- Creating a branch and committing the change
- Opening a pull request and optionally auto-merging it
This approach provides improved visibility and auditability compared to directly committing to the main branch (also, ew). Argo CD then deploys the updated commit. Developers can opt out of auto-merging or create separate PRs for each environment for more granular deployment. Rolling back is as simple as reverting a commit.
Monitoring and Observability
For monitoring, we rely on Datadog’s Argo CD integration, which works exceptionally well. Additionally, Argo CD notifications are sent to a dedicated Slack channel, providing real-time updates on deployment status. While there’s still room for improvement in observability, this simple setup has been effective so far.
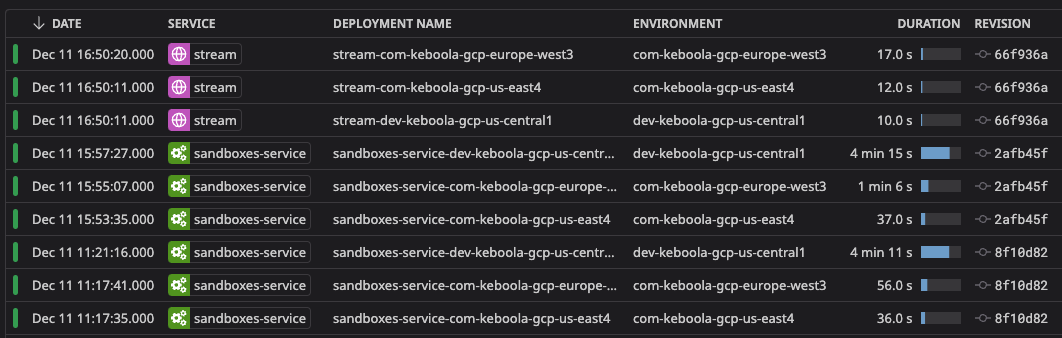
The Argo CD UI has been particularly helpful for debugging and inspecting deployments. Its intuitive interface allows us to quickly identify issues and examine specific components of the deployment process.
Conclusion
Although we’re still in the process of fully migrating to pull-based deployments, the results so far have been promising. While there was initial hesitation among developers to change how they deploy and provision their applications, those who have experienced the new workflow have been impressed by the speed of deployments, the automation built into the continuous delivery process, and the visibility provided by Argo CD’s UI.
Our immediate focus is on migrating the remaining applications to pull-based deployments, starting with GCP. Expanding this model to Azure and AWS will be a larger undertaking, requiring a significant rewrite of their infrastructure definitions into Terraform. However, we’re confident that the foundation we’ve established will allow us to scale this approach across all clouds.
As we move forward, we’ll continue refining our processes and sharing our experiences, both the challenges and the wins, with the broader community.